Role: UX Researcher & Instructor (Embedded)
Timeline: Jan 2023 – May 2025
Tools: Figma, Miro, PostgreSQL, DBeaver, Codeworld, Notebook LM, Qualtrics, R, Python
Methods: Embedded Contextual Inquiry, Longitudinal Usability Studies, Cross-Course Research Synthesis, Student & Teacher Interviews, Surveys, Competitive Analysis
Team: BRBYTES program leadership, LSU Physics and Astrology Staff, East Baton Rouge Public School representatives, Gordon A. Cain Center Faculty
Executive Summary
Challenge: BRBYTES, a nonprofit serving 15,000+ students across 106 Louisiana schools, was delivering its CS and computational thinking courses through a third-party LMS. The tool carried rising licensing costs, created data ownership risks for an NSF-funded research program, offered no integration with BRBYTES’ internal database (SQL) infrastructure, and forced course-specific workarounds that didn’t scale. Leadership was leaning toward building an in-house LMS tool, and needed research evidence to confirm the direction and define what to build.
Approach: Over two years embedded within the BRBYTES program, I built the contextual foundation with consideration to curriculum fluency, school relationships, and teacher trust that made structured UX research possible. The formal research and usability testing phase was conducted in Fall 2024, with a 96-student cohort in my classroom as the primary ethnographic site. I was part of a research team where each of us was assigned to a different BRBYTES course. Rather than study the platform from the outside, I served as the instructor of record for the Introduction to Computational Thinking course at a partner school, running longitudinal usability research across the semester while fellow analysts surfaced parallel findings from the other three courses. We triangulated across courses to separate platform-level frictions from course-specific issues.
Outcome: The research supported BRBYTES’ decision to move off the third-party tool and defined the foundation of what the in-house platform needed to do. Findings translated into a prioritized feature set, separated cleanly into MVP and roadmap, and a prototype admin dashboard was architected from the start to support multiple courses as first-class configurable entities, so BRBYTES can grow its catalog without re-architecting the platform.
Context
The Operational Limit: For a small nonprofit scaling to 106 schools across 37 districts, a per-seat third-party LMS is a growing financial liability. Cost was only the surface issue. The bigger problem was control.
The Research Mission: BRBYTES is not just a course provider. It is an NSF-funded research program whose value proposition depends on measuring student outcomes. An independent Education Northwest evaluation had already shown significant gains in Algebra 1 scores, and the program needed that evidence base to keep growing. A third-party LMS with limited data export, no API, and unclear ownership of student interaction data directly threatens that research mission.
Integration: BRBYTES maintained its own SQL servers and research databases. The existing tool could not be meaningfully integrated with them, forcing manual data reconciliation and making longitudinal analysis across cohorts painful.
Scalability: BRBYTES already delivered seven standalone courses spanning grades 7–12, each with distinct content structures, teacher profiles, and student skill levels. The existing tool forced course-specific workarounds — separate setups, duplicated content structures, manual reconciliation across courses. Any platform BRBYTES built would need to treat courses as first-class, configurable entities so the organization could add to its catalog without re-architecting the system each time.
The question was not “is the LMS tool imperfect?” Every LMS is bound to have some limitations.The question was: what would a platform designed for a research-oriented CS education nonprofit running a portfolio of courses actually look like, and is it worth building?
Research & Discovery
A multi-analyst research team, with one deeply embedded site
BRBYTES staffed a team of UX Analysts, each attached to a different course in the portfolio. My role was unusual even within that team: I took on the instructor of record for the Introduction to Computational Thinking course (Grade 9–10) at a partner school, teaching across the full Fall 2024 semester while running longitudinal research with the 96-student cohort. My fellow analysts surfaced parallel findings from the other three courses through classroom observation, surveys, and teacher interviews. We synthesized findings together, which let us separate platform-level frictions from course-specific issues unique to one curriculum.
While some courses in the BRBYTES catalog share prerequisites and form a partial sequence, each was researched independently as a distinct instructional context. The goal was not to track students across courses but to understand whether platform-level frictions held across different teachers, grade levels, and content types. They did.
Managing the dual-role risk
Embedded instructor-as-researcher is an unusual posture, and worth naming its tradeoffs openly. Dual-role research risks bias in both directions; students may self-censor, and the researcher may see what they want to see. I managed this through structural separation and multiple independent data sources:
- A dedicated Teaching Assistant (TA) handled all grading. Separating the instructor-as-evaluator role from the researcher-as-observer role meant students never had to worry that honest feedback on the platform would affect their grade.
- Daily exit signals. A lightweight emoji-reaction feedback mechanism at the end of each lesson gave me a low-friction read on student state without requiring self-reporting in front of me.
- Survey instruments. Structured surveys at defined points in the semester were administered separately from classroom instruction.
- Cross-analyst triangulation. Because my fellow analysts were running research on different courses, patterns that only showed up in my classroom could be flagged as course-specific; patterns that showed up everywhere could be flagged as platform-level. This was the strongest safeguard against over-generalizing from my single cohort.
- Competitive analysis. Review of other education platforms to benchmark what “good” could look like for this use case.
User Segmentation (The “Who”)
The four courses had overlapping but distinct user profiles. A 7th-grader in Intro to STEM and a 10th-grader in Data Manipulation & Analysis had fundamentally different relationships with the platform, and a math teacher new to CS had different needs from a teacher with a CS background. The personas below are archetypes from the embedded classroom that surfaced consistently across the other three courses in the team’s research.


Representative personas: a first-year CS student and a non-CS-background teacher. These archetypes held across the four courses the team studied, though each course surfaced its own variations.
Key Findings
Across all five research methods and across the four courses the team studied, the same friction points surfaced repeatedly. Some were specific to individual courses; the ones shown below were consistent across the portfolio, which is what made them platform-level problems worth solving.

Top platform-level friction points, weighted by frequency across classroom observation, surveys, and teacher interviews, aggregated across the four courses.
Competitor Research
Before recommending a build, the team benchmarked the existing LMS against the realistic alternatives: a general-purpose LMS like Canvas or Google Classroom, and a CS-specialized platform like Replit for Education. The criteria were weighted toward BRBYTES’ specific needs, such as research-grade data capture, SQL integration, cost sustainability, data ownership, and multi-course scalability rather than general LMS feature breadth.
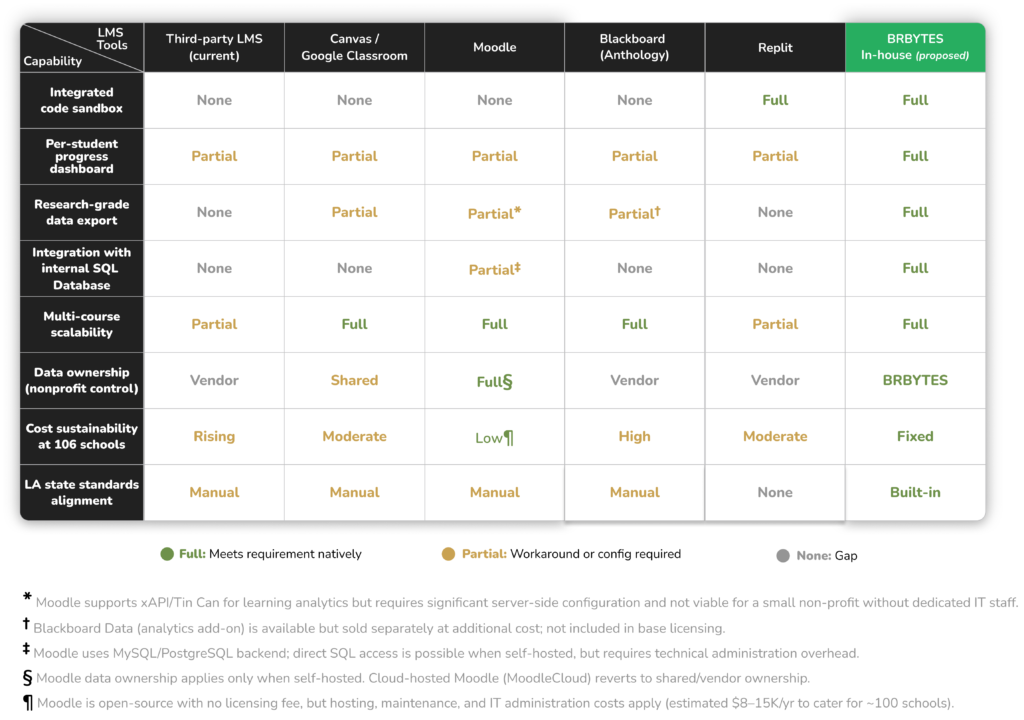
Competitive analysis matrix. No off-the-shelf platform met BRBYTES’ full requirements, particularly around research-grade data ownership, internal SQL integration, and a course-agnostic architecture that could grow with the catalog.
The matrix made the direction concrete. General LMSes handled multi-course scalability but missed research instrumentation. CS-specialized tools solved the sandbox problem but introduced data ownership issues and weren’t architected around course-as-first-class-entity. The intersection BRBYTES actually needed, i.e., a classroom platform and a research instrument in one, built to scale across a growing course catalog, did not exist on the market.
From Findings to Platform
The research produced six feature recommendations. Not all were equal in cost or leverage, and pretending otherwise would have overwhelmed an engineering team with limited capacity. I translated the team’s findings into an impact-vs-effort prioritization so leadership could make a clean MVP vs. roadmap call.
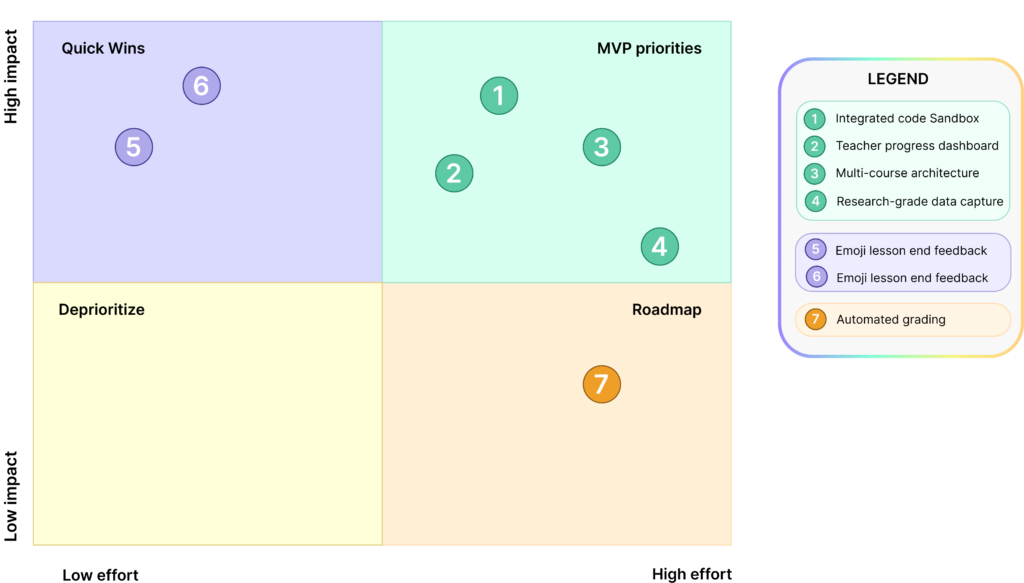
Six research-driven feature recommendations, separated into MVP priorities, quick wins, and roadmap work.
- Integrated code sandbox (MVP). Removed the single highest-cost moment in the student journey that transforms context switching to an external editor; students can submit assignments (without downloading the file and uploading), and give teachers visibility into student work inside a single tool.
- Teacher progress dashboard (MVP). A glanceable view of where each student was stuck and where the class as a whole was blocked. Addressed the top teacher-side pain point across every course the team studied.
- Multi-course architecture (MVP). Treated “course” as a first-class configurable entity, so BRBYTES could add to its seven-course catalog without re-engineering. This was a foundational architectural decision that all other features sit on top of, not an afterthought.
- Research-grade data capture (MVP). Schema-level instrumentation producing clean, ownable data for BRBYTES’ NSF-funded research from day one, with native integration to internal SQL infrastructure.
- Emoji lesson-end feedback (Quick win). The in-classroom pattern used as a research instrument during Fall 2024 scaled into the product as a built-in daily signal. Low engineering cost, high continuous value.
- Automated grading + reduced teacher onboarding (Roadmap). High-leverage but high-effort work, deliberately scoped post-MVP because the research showed they were the next wins, not the blockers for a viable first build.
From Research to Prototype
The first artifact out of this research was the admin-side of the platform, which is the operational backbone that internal program staff use to manage Users, Participants, MOUs, Recruitment, and research Answers across the district network. Because the architecture treats courses as first-class entities, the same admin tools work across the full seven-course catalog without course-specific workarounds. The classroom-facing tools layer on top of this foundation.
BRBYTES in-house platform: admin dashboard, first implementation at BRBYTES Admin Dashboard_v1
Impact
- Confirmed the build direction with documented evidence. Research across four courses supported BRBYTES’ move off the third-party LMS with feature-level justification rather than gut feel.
- Defined the MVP scope. The prioritized feature set that included the integrated sandbox, teacher dashboard, multi-course architecture, research-grade data capture, and embedded feedback became the backbone of the platform specification.
- Architected for growth. Scalability requirements surfaced in research translated directly into a multi-course-first architecture, so BRBYTES can add to its seven-course catalog without replatforming.
- Established a research-informed roadmap. Post-MVP priorities were grounded in documented pain points rather than assumptions.
- Demonstrated the value of coordinated embedded research at scale. The methodology included multiple UX Analysts embedded across the course portfolio, one deeply embedded instructor-researcher as the anchor site, and structural safeguards like a dedicated grading TA, which became a reference pattern for how BRBYTES could study its own classrooms at a 106-school scale.
Reflection
Embedded research of this kind isn’t a universal answer. It works when the domain is rich enough that outside-in methods miss things, and CS instruction in under-resourced schools with wide digital-fluency spread is one of those domains. Teaching the Introduction to Computational Thinking course gave me context that no amount of interview data would have surfaced: which students quietly stopped showing up, which concepts broke the class regardless of how they were introduced, and where a teacher’s time actually went.
Working as part of a research team solved the single-site limitation. On my own, I could only speak credibly about my classroom. With fellow researchers attached to other courses, we could distinguish what was specific to my cohort from what was true about the platform, which is exactly what you need to justify a platform-level build decision.
The honest scaling limitation is that you can’t embed a researcher in every classroom forever. The point of the in-house platform is to scale the signals that embedded research produced: the daily exit emoji, the per-student progress view, and the research-grade data capture. That way, BRBYTES can collect feedback from its users from classrooms at the 106-school scale, not just four.